Bootstrap、Bagging、Boosting、Stacking 都是什么?
- 关键词:Bootstrap – Bagging – Boosting – Stacking
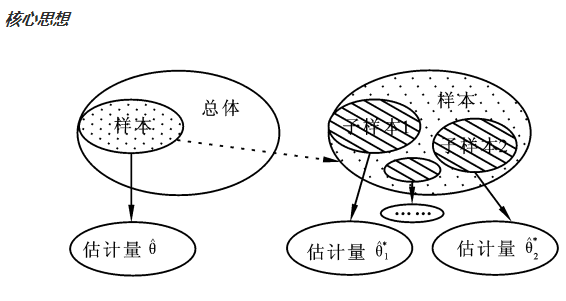
一、Bootstrap
Bootstrap是一种抽样方法,就是一个在自身样本重采样的方法来估计真实分布的问题,在小样本时效果很好。
当我们不知道样本分布的时候,bootstrap方法是最有用的。
子样本之于样本,可以类比样本之于总体
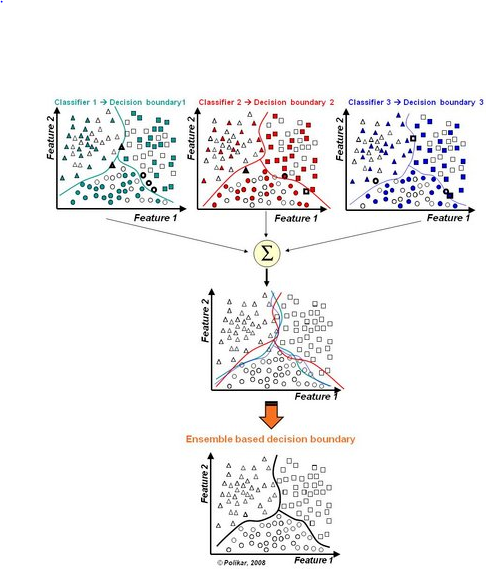
整合多个弱分类器,成为一个强大的分类器。这时候,集合分类器(Boosting, Bagging等)出现了。
二、什么是集成学习(ensemble learning)
在分类的表现上,就是,多个弱分类器组合变成强分类器。
三、Bagging(bootstrap aggregation)
Bagging:从训练集中进行子抽样组成每个基模型所需要的子训练集,对所有基模型预测的结果进行综合,产生最终的预测结果。
Bagging策略过程
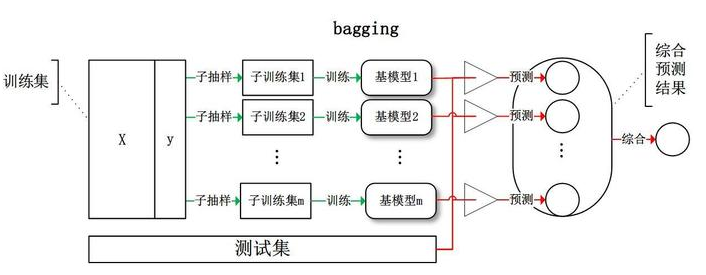
- 从样本集中用Bootstrap采样选出n个训练样本;
- 在所有属性上,用这n个样本训练分类器;
- 重复以上两步m次,就可以得到m个分类器;
- 将数据放在这m个分类器上跑,最后投票机制(多数服从少数),看到底分到哪一类(分类问题)。
Bagging代表算法-Random Forest随机森林
四、Boosting
Boosting采用重赋权法迭代训练基分类器,即对每一轮的训练数据样本赋予一个权重,并且每一轮样本的权值分布依赖于上一轮分类结果;基分类器之间采用序列式线性加权方式进行组合。
Boosting是一种框架算法,用来提高弱分类器准确度的方法,这种方法通过构造一个预测函数序列,然后以一定的方式将他们组合成为一个准确度较高的预测函数。
Boosting算法更加关注错分的样本(对于分类正确的样本权值低,分类错误的样本权值高),这一点和Active Learning相近。
Active Learning:主动学习是半监督机器学习的一个特例,在主动学习中,一个学习算法可以交互式的询问用户(或其他信息源)来获得在新的数据点所期望的输出。
Boosting算法代表–Adaboost(Adaptive Boosting)
一种迭代算法,针对同一个训练集训练不同的分类器(弱分类器),然后进行分类,对于分类正确的样本权值低,分类错误的样本权值高(通常是边界附近的样本),最后的分类器是很多弱分类器的线性叠加(加权组合),分类器相当简单。实际上就是一个简单的弱分类算法提升(boost)的过程。
Adaboosting的自适应在于:前一个基本分类器被错误分类的样本的权重会增大,而正确分类的样本的权重会减小,并再次用来训练下一个基本分类器。同时,在每一轮迭代中,加入一个新的弱分类器,直到达到某个预定的足够小的错误率或最大迭代次数。
Adaboost的优点
- 可以使用各种方法构造子分类器,Adaboost算法提供的是框架
- 简单,不用做特征筛选
- 训练的错误率上界,随着迭代次数的增加,会逐渐下降
- 相比较于RF,更不用担心过拟合问题
Adaboost的缺点
- Adaboost会使得难于分类样本的权值呈指数增长,训练将会过于偏向这类困难的样本,导致Adaboost算法易受噪声干扰。
- Adaboost对于噪音数据和异常数据是十分敏感的
- Adaboost是一种”串行”算法.所以GBDT(Gradient Boosting Decision Tree)也非常慢
- Adaboost依赖于弱分类器,而弱分类器的训练时间往往很长。
Gradient Boosting Decision Tree(梯度提升决策树)——–待更新
五、Stacking
将训练好的所有基模型对整个训练集进行预测,第j个基模型对第i个训练样本的预测值将作为新的训练集中第i个样本的第j个特征值,最后基于新的训练集进行训练。同理,预测的过程也要先经过所有基模型的预测形成新的测试集,最后再对测试集进行预测。
Stacking是一种截然不同的组合多个模型的方法,它讲的是组合学习器的概念,具体的过程如下:
- 划分训练数据集为两个不相交的集合
- 在第一个集合上训练多个学习器
- 在第二个集合上测试这几个学习器
- 把第三步得到的预测结果作为输入,把正确的回应作为输出,训练一个高层学习器