在变量(列)的使用和数据(行)的使用上进行随机化,生成很多分类树,再汇总分类树的结果
- 关键词:随机森林 – 决策树
一、随机森林
随机森林顾名思义,是用随机的方式建立一个森林,森林里面有很多的决策树组成,随机森林的每一棵决策树之间是没有关联的。在得到森林之后,当有一个新的输入样本进入的时候,就让森林中的每一棵决策树分别进行一下判断,看看这个样本应该属于哪一类(对于分类算法),然后看看哪一类被选择最多,就预测这个样本为那一类。
1.训练样本选择方面的Random
Bootstrap方法随机选择子样本。
2.特征选择方面的Random
属性集中随机选择k个属性,每个树节点分裂时,从这随机的k个属性,选择最优的。
Bagging代表算法-随机森林(Random Forest)
二、随机森林优点和缺点
优点
1.在数据集上表现良好,两个随机性的引入,使得随机森林不容易陷入过拟合;
2.在当前的很多数据集上,相对其他算法有着很大的优势,两个随机性的引入,使得随机森林具有很好的抗噪声能力;
3.它能够处理很高维度(feature很多)的数据,并且不用做特征选择,对数据集的适应能力强:既能处理离散型数据,也能处理连续型数据,数据集无需规范化;
4.可生成一个矩阵,用于度量样本之间的相似性:, 表示样本i和j出现在随机森林中同一个叶子结点的次数,N随机森林中树的颗数;
5.在创建随机森林的时候,对generlization error使用的是无偏估计;
6.训练速度快,可以得到变量重要性排序(两种:基于OOB误分率的增加量和基于分裂时的GINI下降量);
7.在训练过程中,能够检测到feature间的互相影响;
8.容易做成并行化方法;
9.实现比较简单。
缺点
1.随机森林在解决回归问题时并没有像它在分类中表现的那么好,这是因为它并不能给出一个连续型的输出。当进行回归时,随机森林不能够作出超越训练集数据范围的预测,这可能导致在对某些还有特定噪声的数据进行建模时出现过度拟合;
2.对于许多统计建模者来说,随机森林给人的感觉像是一个黑盒子——你几乎无法控制模型内部的运行,只能在不同的参数和随机种子之间进行尝试。
三、随机森林应用范围
随机森林主要应用于回归和分类。
以决策树为基本模型的bagging在每次bootstrap放回抽样之后,产生一棵决策树,抽多少样本就生成多少棵树,在生成这些树的时候没有进行更多的干预。
随机森林也是进行bootstrap抽样,但它与bagging的区别是:在生成每棵树的时候,每个节点变量都仅仅在随机选出的少数变量中产生。因此,不但样本是随机的,连每个节点变量(Features)的产生都是随机的。
随机森林(random forest)是一种利用多个分类树对数据进行判别与分类的方法,它在对数据进行分类的同时,还可以给出各个变量(基因)的重要性评分,评估各个变量在分类中所起的作用。
四、随机森林理论介绍
1. 随机森林基本原理
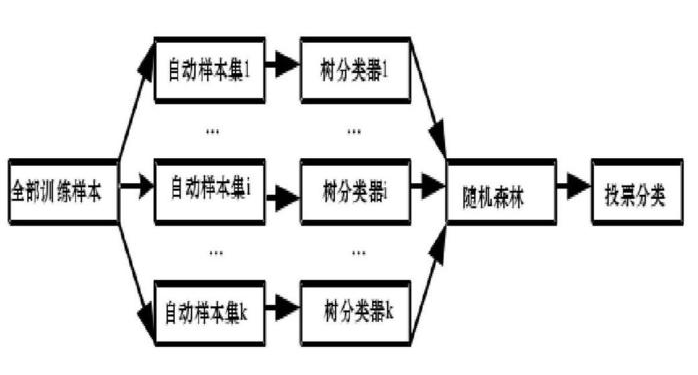
随机森林,从原始训练样本集N中有放回地重复随机抽取k个样本生成新的训练样本集合,然后根据自助样本集生成k个分类树组成随机森林,新数据的分类结果按分类树投票多少形成的分数而定。
森林中的每棵树具有相同的分布,分类误差取决于每一棵树的分类能力和它们之间的相关性。
特征选择采用随机的方法去分裂每一个节点,然后比较不同情况下产生的误差。能够检测到的内在估计误差、分类能力和相关性决定选择特征的数目。
单棵树的分类能力可能很小,但在随机产生大量的决策树后,一个测试样品可以通过每一棵树的分类结果经统计后选择最可能的分类。
2. 随机森林算法
在建立每一棵决策树的过程中,有两点需要注意:采样与完全分裂。
首先是两个随机采样的过程,随机森林对输入的数据要进行行、列的采样。
对于行采样,采用有放回的方式,也就是在采样得到的样本集合中,可能有重复的样本。假设输入样本为N个,那么采样的样本也为N个。这样使得在训练的时候,每一棵树的输入样本都不是全部的样本,使得相对不容易出现over-fitting。
对于列采样,从M个feature中,选择m个(m « M)。
对采样之后的数据使用完全分裂的方式建立出决策树,这样决策树的某一个叶子节点要么是无法继续分裂的,要么里面的所有样本的都是指向的同一个分类。
3. 决策树中分裂属性的两个选择度量
- 信息增益
- 基尼指数
4. 随机森林模型的注意点
设有N个样本,每个样本有M个features,决策树们其实都是随机地接受n个样本(对行随机取样)的m个feature(对列进行随机取样),每颗决策树的m个feature相同。每颗决策树其实都是对特定的数据进行学习归纳出分类方法,而随机取样可以保证有重复样本被不同决策树分类,这样就可以对不同决策树的分类能力做个评价。
5. 随机森林实现过程
1.原始训练集为N,应用bootstrap法有放回地随机抽取k个新的自助样本集,并由此构建k棵分类树,每次未被抽到的样本组成了k个袋外数据;
2.设有mall个变量,则在每一棵树的每个节点处随机抽取mtry个变量(mtry n mall),然后在mtry中选择一个最具有分类能力的变量,变量分类的阈值通过检查每一个分类点确定;
3.每棵树最大限度地生长, 不做任何修剪;
4.将生成的多棵分类树组成随机森林,用随机森林分类器对新的数据进行判别与分类,分类结果按树分类器的投票多少而定。