个性化推荐系统应用–电子商务-电影和视频-音乐-社交-阅读-基于位置的服务-邮件-广告
- 关键词:推荐系统 – 算法总结
一、推荐系统测评及实验方法
评测指标(测评维度:用户、物品、时间)
- 用户满意度
我们可以用点击率、用户停留时间和转化率等指标度量用户的满意度。
- 预测准确度
评分预测(RMSE和MAE)
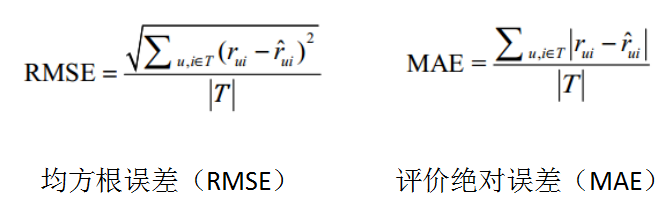
用python代码求RMSE和MAE:
//records[i] = [用户(u),物品(i),实际评分(rui),预测评分(pui)]
def RMSE(records):
return math.sqrt(sum([(rui-pui)*(rui-pui) for u,i,rui,pui in records]) / float(len(records)))
def MAE(records):
return sum([abs(rui-pui) for u,i,rui,pui in records]) / float(len(records))
RMSE加大了对预测不准的用户物品评分的惩罚(平方项的惩罚),因而对系统的评测更加苛刻。
如果评分系统是基于整数建立的(即用户给的评分都是整数),那么对预测结果取整会降低MAE的误差。
TopN推荐(个性化的推荐列表)
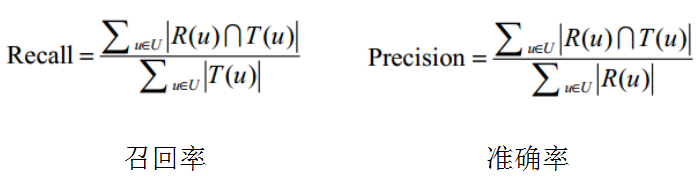
精确率(precision)/召回率(recall),R(u)是用户在训练集上的行为,T(u)是用户在测试集上的行为
准确率-精确率-召回率(举例说明)

召回率描述有多少比例的用户—物品评分记录包含在最终的推荐列表中(它表示的是样本中的正例有多少被预测正确了,一种是把原来的正类预测成正类(TP),另一种就是把原来的正类预测为负类(FN))
精确率描述最终的推荐列表中有多少比例是发生过的用户—物品评分记录(它表示的是预测为正的样本中有多少是真正的正样本,一种就是把正类预测为正类(TP),另一种就是把负类预测为正类(FP))
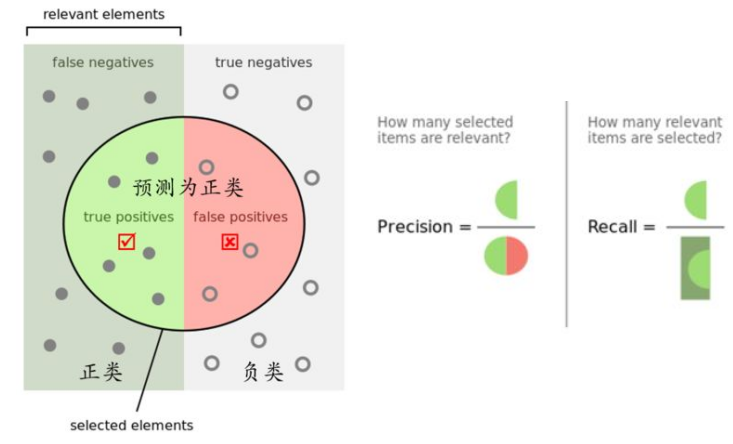
其实就是分母不同,一个分母是预测为正的样本数,另一个是原来样本中所有的正样本数
用python代码求precision和recall:
def PrecisionRecall(test, N):
hit = 0
n_recall = 0
n_precision = 0
for user, items in test.items():
rank = Recommend(user, N)
hit += len(rank & items)
n_recall += len(items)
n_precision += N
return [hit / (1.0 * n_recall), hit / (1.0 * n_precision)]
- 覆盖率(描述一个推荐系统对物品长尾的发掘能力)
假设系统的用户集合为U,推荐系统给每个用户推荐一个长度为N的物品列表R(u):
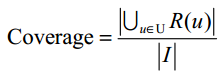
一个好的推荐系统不仅需要有比较高的用户满意度,也要有较高的覆盖率。为了更细致地描述推荐系统发掘长尾的能力,需要统计推荐列表中不同物品出现次数的分布。如果所有的物品都出现在推荐列表中,且出现的次数差不多,那么推荐系统发掘长尾的能力就很好。
在信息论和经济学中有两个著名的指标可以用来定义覆盖率
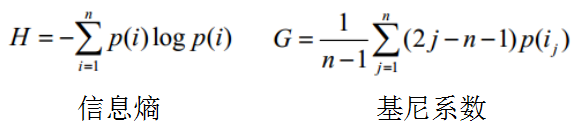
这里p(i)是物品i的流行度除以所有物品流行度之和
这里是按照物品流行度p()从小到大排序的物品列表中第j个物品
用python代码计算给定物品流行度分布后的基尼系数:
def GiniIndex(p):
j = 1
n = len(p)
G = 0
for item, weight in sorted(p.items(), key = itemgetter(1)):
G += (2 * j - n - 1) * weight
return G / float(n - 1)
基尼系数的计算原理

马太效应,即所谓强者更强,弱者更弱的效应。
评测推荐系统是否具有马太效应的简单办法就是使用基尼系数。如果G1是从初始用户行为中计算出的物品流行度的基尼系数,G2是从推荐列表中计算出的物品流行度的基尼系数,那么如果G2>G1,就说明推荐算法具有马太效应。
- 多样性(描述了推荐列表中物品两两之间的不相似性)
假设s(i,j)属于[0,1]定义了物品i和j之间的相似度,那么用户u的推荐列表R(u)的多样性定义如下
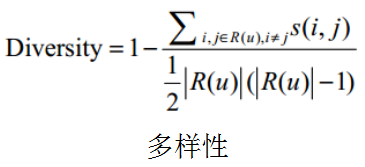
推荐系统的整体多样性可以定义为所有用户推荐列表多样性的平均值
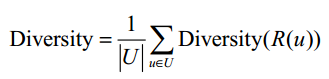
- 新颖性-惊喜度-信任度-实时性-健壮性-商业目标
新颖性:在一个网站中实现新颖性的最简单办法是,把那些用户之前在网站中对其有过行为的物品从推荐列表中过滤掉。
信任度:度量推荐系统的信任度只能通过问卷调查的方式,提高推荐系统的信任度主要有两种方法:首先需要增加推荐系统的透明度,而增加推荐系统透明度的主要办法是提供推荐解释;其次是考虑用户的社交网络信息,利用用户的好友信息给用户做推荐,并且用好友进行推荐解释。
实时性:需要实时地更新推荐列表来满足用户新的行为变化;需要能够将新加入系统的物品推荐给用户,这主要考验了推荐系统处理物品冷启动的能力。
健壮性:衡量了一个推荐系统抗击作弊的能力。提高系统的健壮性,除了选择健壮性高的算法,还有:设计推荐系统时尽量使用代价比较高的用户行为;在使用数据前,进行攻击检测,从而对数据进行清理。
商业目标:设计推荐系统时需要考虑最终的商业目标,而网站使用推荐系统的目的除了满足用户发现内容的需求,也需要利用推荐系统加快实现商业上的指标。
离线实验
- 通过日志系统获得用户行为数据,并按照一定格式生成一个标准的数据集;
- 将数据集按照一定的规则分成训练集和测试集;
- 在训练集上训练用户兴趣模型,在测试集上进行预测;
- 通过事先定义的离线指标评测算法在测试集上的预测结果。
离线实验优缺点

用户调查
因此,如果要准确评测一个算法,需要相对比较真实的环境。最好的方法就是将算法直接上线测试,但在对算法会不会降低用户满意度不太有把握的情况下,上线测试具有较高的风险,所以在上线测试前一般需要做一次称为用户调查的测试。
在线实验
在完成离线实验和必要的用户调查后,可以将推荐系统上线做AB测试(AB测试是一种很常用的在线评测算法的实验方法。它通过一定的规则将用户随机分成几组,并对不同组的用户采用不同的算法,然后通过统计不同组用户的各种不同的评测指标比较不同算法,比如可以统计不同组用户的点击率,通过点击率比较不同算法的性能。)
AB测试的优缺点:
- 可以公平获得不同算法实际在线时的性能指标;
- 周期比较长,必须进行长期的实验才能得到可靠的结果,故只是用它测试那些在离线实验和用户调查中表现很好的算法;
- AB测试系统的设计也是一项复杂的工程,切分流量是AB测试中的关键。
AB测试系统
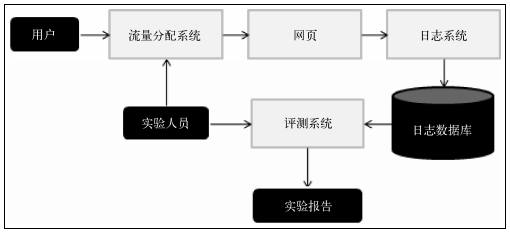
二、利用用户行为数据
用户行为数据
显性反馈数据和隐性反馈数据

用户行为分析
互联网上的很多数据分布都满足一种称为Power Law③的分布,这个分布在互联网领域也称长尾分布:
用户活跃度和物品流行度的分布
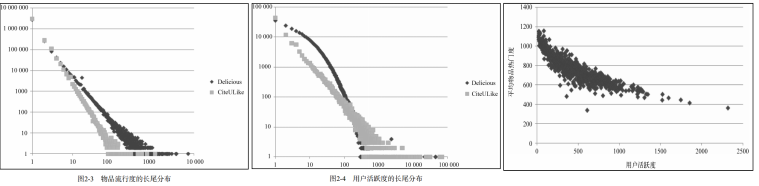
仅仅基于用户行为数据设计的推荐算法一般称为协同过滤算法:基于邻域的方法、隐语义模型、基于图的随机游走算法等。
最广泛应用的算法是基于邻域的方法:基于用户的协同过滤算法和基于物品的协同过滤算法。
实验设计和算法评测
数据集按照均匀分布随机分成M份
//每次实验选取不同的k(0≤k≤M-1)和相同的随机数种子seed
def SplitData(data, M, k, seed):
test = []
train = []
random.seed(seed)
for user, item in data:
if random.randint(0,M) == k:
test.append([user,item])
else:
train.append([user,item])
return train, test
评测指标(精确率/召回率、覆盖率)
基于邻域的算法(基于用户的协同过滤算法和基于物品的协同过滤算法)
- 基于用户的协同过滤算法
基于用户的协同过滤算法主要包括两个步骤:(1) 找到和目标用户兴趣相似的用户集合;(2) 找到这个集合中的用户喜欢的,且目标用户没有听说过的物品推荐给目标用户。
步骤(1)的关键就是计算两个用户的兴趣相似度:协同过滤算法主要利用行为的相似度计算兴趣的相似度。
基于物品的协同过滤算法