要成功地使用深度学习技术,仅仅知道存在哪些算法和解释他们为何有效的原理是不够的。
在机器学习系统的日常开发中,实践者需要决定是否收集更多的数据、增加或减少模型容量、添加或删除正则化项、改进模型的优化、改进模型的近似推断或调试模型的软件实现。
- 关键词:实践方法 – 学习模型 – 训练模型 – 目标函数
一、实践设计流程
1.确定目标
使用什么样的误差度量,并为此误差度量指定目标值。对于大多数应用而言,不可能实现绝对零误差。
比如:度量精度(precision)和召回率(recall),我们通常会画PR曲线(PR curve),y轴表示精度,x轴表示召回率。
比如:我们希望用一个数而不是曲线来概括分类器的性能。要做到这一点,我们可以将精度p和召回率r转换为F分数(F-score)。
比如:一种自然的性能度量是覆盖(coverage)。覆盖是机器学习系统能够产生响应的样本所占的比率。我们权衡覆盖和精度。
比如:我们可以度量点击率、收集用户满意度调查。
2.尽快建立一个端到端的工作流程
根据问题的复杂性:
- 如果只需正确地选择几个线性权重就可能解决问题,那么项目可以开始于一个简单的统计模型,如逻辑回归。
- 如果问题属于 “AI-完全’’ 类的,如对象识别、语音识别、机器翻译等等,那么项目开始于一个合适的深度学习模型,效果会比较好。
比如:项目是以固定大小的向量作为输入的监督学习,那么可以使用全连接的前馈网络。
比如:如果输入有已知的拓扑结构(例如,输入是图像),那么可以使用卷积网络。
比如:输入或输出是一个序列,可以使用门控循环网络(LSTM 或 GRU)。
3.搭建系统,并确定性能瓶颈检查哪个部分的性能差于预期,以及是否是因为过拟合、欠拟合,或者数据或软件缺陷造成的
4.根据具体观察反复地进行增量式的改动,如收集新数据、调整超参数或改进算法
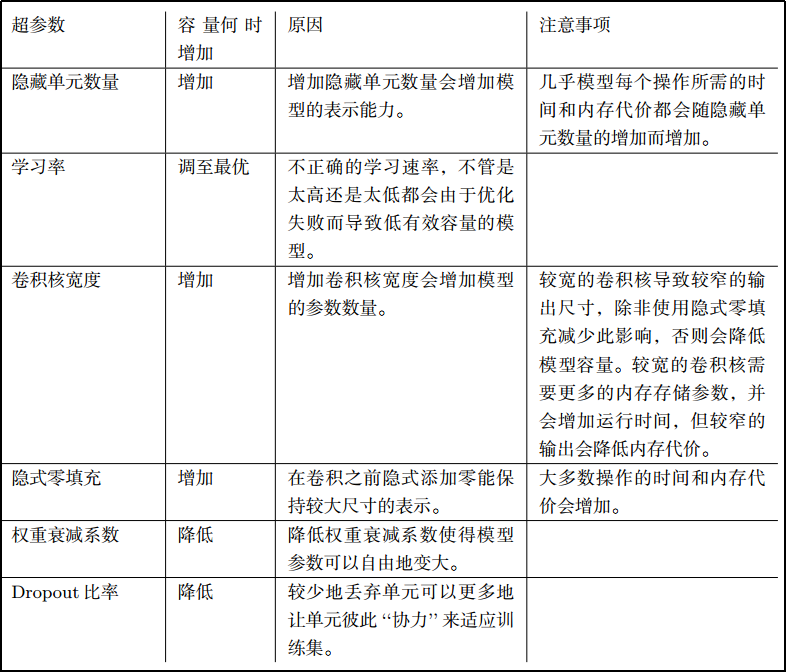
各种超参数对模型容量的影响